Introduction
What if phone recognize songs without the hassle of opening an app? This paper introduces Now Playing, an innovative music recognition system that consumes low energy and operates continuously on device instead of solutions like Shazam or SoundHound that uses servers for recognition.
This blog unpacks how Now Playing system tackles challenges in music recognition, focusing on neural network part of the system.
The Problem
- According to the paper, traditional systems depends on server-side computation, so we required to make API call over the internet, and to make calls continuously for recognition is infeasible and power consuming.
- For continuous recognition, we have to address three problems:
- High Energy Demand: Keeping device's main processor active for real-time recognition will drain the battery.
- Privacy Concerns: sending audio data continuously to external servers risks user privacy.
- Real-Time Constraints: Users expect instant identification without manual intervention.
The Solution
This paper presents the music recognizer build using combining state-of-the-art neural network and hardware optimization. Here's how it works:
1. Music detection
- To avoid the main processor running continuously, They introduce piece of hardware Digital Signal Processor (DSP), which runs continuously . It's job will be to detect ambient music and wake the device processor for further recognition.
- It only invokes processor when it is sure that ambient music is detected saving energy consumption.
After music is detected using DSP. The fingerprinter is ran, it's job is to convert incoming audio into embedding, known as fingerprint . This embedding is used further to search in the database against other embedding.
2. Neural network fingerprinter
- The neural network fingerprinter (NNF) job is to analyze a few seconds of audio and emits a single embedding at a rate of one per second.
- The neural network fingerprinter architecture consist of Convolutions and divide-and-encode layers (full connected layers).
- The Architecture:
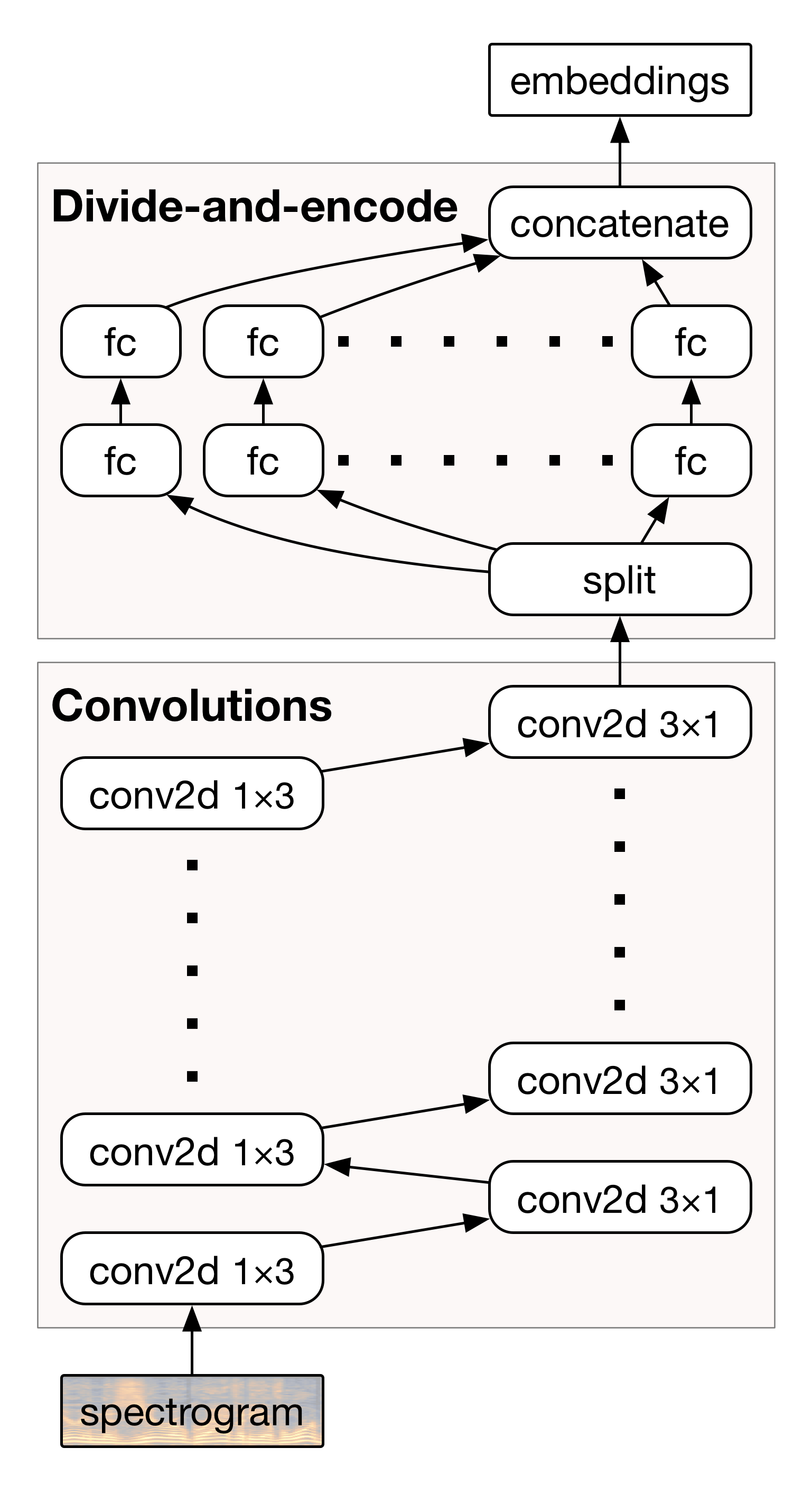
Image Ref: Now Playing: Continuous low-power music recognition
- All layers except for the final divide-and-encode layer use the ELU activation function and batch normalization.
- The network is trained using the triplet loss function, which uses three audio segments anchor positive audio segment, negative audio segment, we tried to minimize the anchor and positive audio segment distance while increasing distance of anchor and negative audio segment.
- Training: The manipulated the data by adding noise to mimic the real-world scenarios. ensuring robustness.
- Efficiency: Fingerprints (embeddings) are quite compressed taking less than 3KB per song. Enabling us to store tens of thous
3. Fingerprint Matching
- After NNFP (neural network fingerprinter) spit out embedding we use it to match with the fingerprints sequence in the song database which most closely matches the sequence of fingerprints generated by the query audio.
- Approximate search: Quickly identifies potential matches using nearest neighbor techniques
- Fine-Grained scoring: Refines matches with sequences similarity metrics.
Results
The research demonstrated impressive performance across multiple dimensions:
- Recognition Accuracy:
- Fingerprints with 96 dimensions struck a balance between storage efficiency and accuracy, achieving precision and recall rates close to larger models.
- We can increase the accuracy by creating bigger fingerprints but it will increase storage. We have to consider space-accuracy trade-off.
- Energy Efficiency:
- The system consumes less than 1% of daily battery usage on a Pixel 2 device, even when running continuously.
- The DSP-based music detector adds only 0.4mA to standby power consumption.
- Privacy Protection:
- All computations occur on the device, ensuring no data leaves the user’s phone.
Reference
- Now Playing: Continuous low-power music recognition
- FaceNet: A Unified Embedding for Face Recognition and Clustering
- Simultaneous Feature Learning and Hash Coding with Deep Neural Networks